
2012 was a fun year because the popularity of Twitter growing and strong. It was a channel that the general public was using to voice their opinions of anything and everything. In an experiment I wanted to see if popular opinion could predict the NFL Draft.
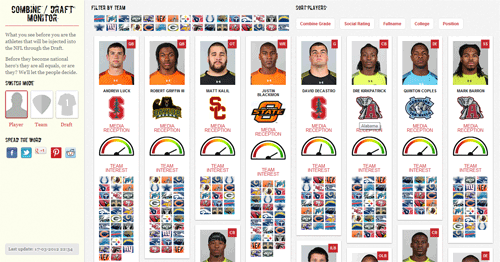
The dashboard look was epic!
To make this happen actually required a bit of architecture planning and stitching multiple systems together. Using Twitter and the stream API was perfect for our source of data, it just works. But I also needed player and team information to connect mentions of players and teams together. Finally a series of sentiment analysis systems to capture positive or negative comments and filters to remove noise.
First work was implementing the Twitter Stream API, listening for everything that mentioned "nfl draft" keywords. This data is collected and rotated into JSON files for the next system to pickup and process. This is a lot of data as you can imagine so the implementation of a monitoring and alerting system was improtant if any of these systems stopped working because it would have a knock-on impact to the whole system.

Now we have continuous data flowing into our system, next came came the crutial step of taking the data we wanted, linking teams and players and then storing this in our database. Having all the players names for the Draft was key, so scouting all of the large websites to collect their names was time consuming but also great to get a sense of each of these players. What is really important is having everyone who is eligible for the draft in your system, because the reality is we wont know if they plan to declare until the end of the college season and they make that decision.
When prospect players are mentioned they are often linked to potential teams, and this is the exciting part as this creates a picture of who could go where! Taking into account for team abbreviations and nicknames helps here too, but also filtering as its quite common for players for to have the same surname as a NFL team. (e.g Washington) or they may be mentioned in reference to their college and not the NFL team (e.g Miami Tech vs Miami Dolphins)
I was quite adventurous at the time and wanted to perform sentiment analysis on tweets (140 characters) which now I see was impossible, its just not enough when you consider tags, internet talk and general lack of sentence structure. It was interesting and enjoyable to do training of a naive bayes algorithm and observe the results, it wasnt great but it worked. Im really glad I didnt go down the rabbit hole of auto-training because without rigourous quality checking these systems spin out of control.
A this stage we have a database full of prospect player connections to teams so the next step was plugging in the NFL Draft order and building a system that would take the mappings and simulate the 7 rounds of the draft. I loved this part as it was in the early stages throwing up some quite random results, but its a system that worked really well. Of course the adage "quality in, quality out" rules here and it took time to see the more realistic picks rise to the top.
The draft selection process originally took the most 'popular' player based on the current team pick and selected them blindly, which basically resulted in a first round draft full of quarter backs. I am always hesitant to hard code rules into system but something needed to be done to ensure this scenario was avoided. The solution was that before the draft simulation ran it constructed a list of 'needed positions' based on the teams connection strengths to prospect players and for each team pick the list was referenced to make the decision on which player to take. The results were that we didnt have repeated picks and fascinating outputs in comparison to some 'big boards' were happening! It wasnt perfect, eventually adding statistical guard rails complimented the picks which made it an eligant solution.
This is the part of the work where you now have your very own data source to play with, its so much fun building visualisations and tools to inspect the data.

I thought it would be good to share what I was working on with the internet, and to my surprise there are many data nerds like me who are really into this sort of stuff. They provided excellent feedback and eventually it had a life of its own being featured on official supporter forums and even local radio stations! I had major interest from sporting networks and outlets who had never seen anything like this before.
This website ran on a single node system, with a LAMP architecture, fronted by Varnish. It served well over 250 million views and at the peak leading upto the draft ~40,000 requests per second. Fun stuff!

Andrew Luck
Andrew Luck was the first round pick for the Colts, the system got that and many other predictions spot on. Once the draft was over for the year it was time to turn off the lights and work on something else.
•